
Les serveurs WEB constituent la base du WWW. Le WWW, ou « World Wide Web », est un système de gestion de documents hypertextuels. En effet, il permet aux utilisateurs d’accéder à des documents électroniques liés entre eux par des liens hypertexte. Comme nous l’expliquerons plus tard, un serveur web héberge ces documents Dans les faits, ces documents, qui sont un ensemble d’informations, peuvent être consultés à distance.
Tim Berners-Lee, un scientifique anglais, a créé le World Wide Web dans les années 1990 lorsqu’il travaillait au CERN (Conseil Européen pour la Recherche Nucléaire). Le World Wide Web est né dans le cadre d’un projet permettant aux scientifiques de partager leurs travaux. Comme toute communication informatique, l’échange s’appuie sur un modèle standardisé nommé TCP/IP.
Le modèle TCP/IP : La base de la communication entre Serveur Web et client
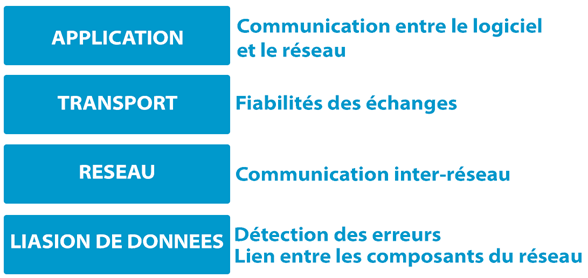
L’IETF a défini le modèle TCP/IP dans les documents RFC791 et RFC793. Il le décompose en 4 couches. Chacune de ces couches joue un rôle spécifique et s’appuie sur des protocoles pour remplir ses fonctions. Pour illustrer son fonctionnement, imaginez un bâtiment de 4 étages sans ascenseur. Pour se rendre au 4ème étage, il faut d’abord passer par le 1er, puis le 2ème, ensuite le 3ème, et enfin arriver au 4ème. On ne peut pas aller du 1er au 3ème sans passer par le 2ème étage. Tim Berners-Lee a créé le protocole HTTP pour être conforme à la logique de ce modèle de communication. Nous le situons dans la couche « Application » du modèle TCP/IP.
L’acronyme WWW (World Wide Web) et les URL
Le terme WWW est souvent utilisé dans les adresses URL (Uniform Resource Locator) pour identifier un site web accessible par un lien hypertexte. Pour accéder à ces pages, nous avons besoin d’un navigateur qui transformera notre clic sur un lien hypertexte en requête HTTP. La machine où est installé le navigateur qui nous permet d’envoyer une requête est le client, et la machine qui reçoit et traite la requête est le serveur.

En effet, cette illustration offre une vision simplifiée de la communication, mais elle met en évidence l’importance du protocole HTTP dans le World Wide Web
Le protocole TCP dans les serveurs WEB

Avant que le client puisse envoyer une requête HTTP, il doit établir une connexion TCP. Cette phase permet au client et au serveur de négocier les paramètres de connexion pour garantir que les données transmises seront correctement reçues et dans l’ordre. Le client et le serveur utilisent le processus « Three-way handshake » pour établir la connexion.
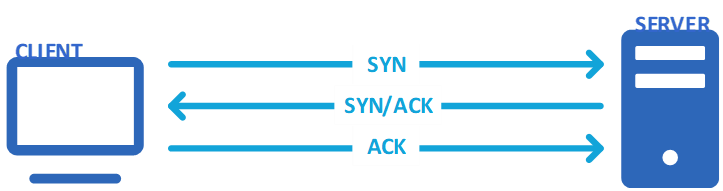
Le premier échange consiste en un paquet SYN envoyé par le client au serveur, ce paquet demande l’établissement de la connexion. Le serveur renvoie une requête SYN/ACK avec les options de connexion. Le client répond en envoyant un paquet ACK. Ce message indique au serveur qu’il a bien reçu les informations et qu’il est prêt à commencer les échanges.
Le protocole HTTP
La RFC1945 a standardisé le protocole HTTP en 1996. Cette RFC décrit les méthodes de requêtes, les codes de statut et les en-têtes. Une seconde RFC, la RFC 2616, publiée en 1999, ajoute des fonctionnalités qui permet de réduire la latence.
La version 2 du protocole HTTP ajoute des fonctionnalités de compression et de multiplexage de requêtes, ce qui améliore la vitesse de chargement. Elle intègre aussi une couche de sécurité imposant le chiffrement des requêtes. Actuellement, un travail sur la version 3 est en cours. En effet, cette nouvelle version s’appuiera sur le protocole QUIC au lieu de TCP. Ainsi le « Three-Way Handshake » sera supprimé, ce qui aura pour effet les requêtes. En observant les différentes versions du protocole, nous remarquons que l’accent est mis sur la rapidité d’exécution des requêtes HTTP et la sécurité.
Les requêtes HTTP 1.0
Une requête HTTP comprend une méthode qui spécifie l’action à effectuer sur une ressource. Dans la version HTTP/1.0, les méthodes prises en charge étaient :
- GET : utilisée pour récupérer des informations depuis le serveur.
- POST : utilisée pour envoyer des informations au serveur pour une utilisation ultérieure.
- HEAD : utilisée pour ne renvoyer que les en-têtes d’une réponse HTTP.
Les requêtes HTTP 1.1
Le protocole HTTP a été conçu pour l’échange de travaux scientifiques et non pour un usage commercial. Ces méthodes étaient suffisantes à l’époque. Cependant, avec l’essor commercial d’Internet, les quatre méthodes listées sont devenues insuffisantes. Il manquait la gestion des sessions, permettant, entre autres, à un utilisateur de s’identifier sur un site internet et de maintenir sa session active même lors de la navigation entre les pages. La version HTTP/1.1 a ajouté les méthodes suivantes :
- PUT : utilisée pour envoyer des données à un serveur pour créer ou remplacer une ressource.
- DELETE : utilisée pour supprimer une ressource sur un serveur.
- TRACE : utilisée pour envoyer une requête pour déboguer.
- OPTIONS : utilisée pour découvrir les options disponibles pour une URL donnée.
- CONNECT : utilisée pour établir une connexion à travers un proxy.
- PATCH : utilisée pour envoyer des modifications partielles à une ressource sur le serveur..

Bon à savoir :
Dans la version http/2, les méthodes seront les mêmes que pour HTTP/1.1, la différence va être sur les fonctionnalités, permettant ainsi de traiter des requêtes multiples en simultanés.
Le client recevra alors une réponse du serveur web contenant un statut sous la forme d’un code d’état, classé en cinq catégories :
- La classe 1XX : indique que la requête a été reçue et bien interprétée, mais qu’elle n’a pas encore été traitée.
- La classe 2XX : indique que la requête a été traitée avec succès.
- La classe 3XX : indique que le serveur a besoin de plus d’informations pour traiter la requête (par exemple, une redirection vers une autre URL).
- La classe 4XX : indique que la requête contient une erreur.
- La classe 5XX : indique que le serveur a rencontré une erreur en tentant de traiter la requête.